
1、工具
jupyter notebook 编辑器, Windows系统
说明:
jupyter notebook 编辑器 可以下载annconda是附带。也可以单独在power shell里:
1 | pip install jupyter |
下载压缩包解压下来即可。
2、开始
-
找到所在的 ipynb 文件目录下
-
按住shift点击鼠标右键,找到打开power shell
-
在命令行输入
1
jupyter notebook
加载完过一会浏览器就会弹出来窗口,没弹出来就自己在浏览器的网址输入http://localhost:8888/

3、介绍
html文件
每一个网页都是一份 HTML文档,全称叫 hypertext markup language,是一种文本标记语言,标签含义如下图所示:
<!DOCTYPE html> 声明为HTML5 文档
<html> 元素是HTML网页的根元素
<head> 元素包含了文档的元(meta) 数据,如<meta charset="utf-8">定义网页编码格式为utf-8
<title> 元素描述了文档的标题
<body> 元素包含了可见的页面内容
<h1> 元素定义一个大标题
<p> 元素定义一个段落 HTML
声明为HTML5 文档
元素是HTML网页的根元素
元素包含了文档的元(meta) 数据,如定义网页编码格式为utf-8
网页中在打开开发者模式下,按F12可以查看页面源代码,也就是html源文件。
4、Requests
为什么要学习requests,而不是urllib?
- requests的底层实现就是urllib。
- requests在python2和python3中通用,方法完全一样。
- requests简单易用。
- requests能够自动帮我们解压(gzip压缩等)网页内容
requests的作用 作用:
requests的用法
requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多
因为是第三方库,所以使用前需要cmd安装
基本用法:requests.get()用于请求目标网站,类型是一个HTTPresponse类型
1 | import requests |
request常用的有两种请求方法:get方法和post方法
1 | #各种请求方法 |
数据类型
① 数据分两种形式:非结构化数据、结构化数据。
- 非结构化数据html等
处理方法:正则表达式、Xpath。
- 结构化数据:json、xml等
处理方法:转化为python数据类型。
基本用法
基本的get请求:
1 | import requests |
1 | # 带参数的GET请求: |
1 | import requests |
1 | # 简单保存一个二进制文件(以图片为例子) |
图片保存格式上png为什么和jpg没什么区别?
response.text和response.content的区别:
response.text 类型:
str 解码类型:根据HTTP头部对响应的编码做出有根据的推测,推测的文本编码 如何修改编码方式:response.encoding=“gbk”
response.content 类型:
bytes 解码类型:没有指定 如何修改编码方式:response.content.decode(“utf8”)
5、高级:
为你的请求添加头信息:
1 | import requests |
头文件的作用:
1 | # 获取cookies |
cookie和session的区别
- cookie数据存放在客户的浏览器上,session数据放在服务器上
- cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗 考虑到安全应当使用session。
- session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能, 考虑到减轻服务器性能方面,应当使用COOKIE。
- 单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
cookie 的作用:
处理cookie和session
- 带上cookie和session的好处: 能够请求到登陆后的页面
- 带上cookie和session的弊端: 一套cookie和session往往对应一个用户,请求太快 请求次数太多,容易被识别为爬虫 不需要cookie的时候尽量不去使用cookie
- 有时为了获取登陆的页面,必须发送带有cookie的请求
6、数据提取
数据提取就是从响应中获取我们想要的数据的过程。
数据分类:
非结构化的数据:html等
处理方法:正则表达式、xpath
结构化数据:json,xml等
处理方法:转化为python数据类型
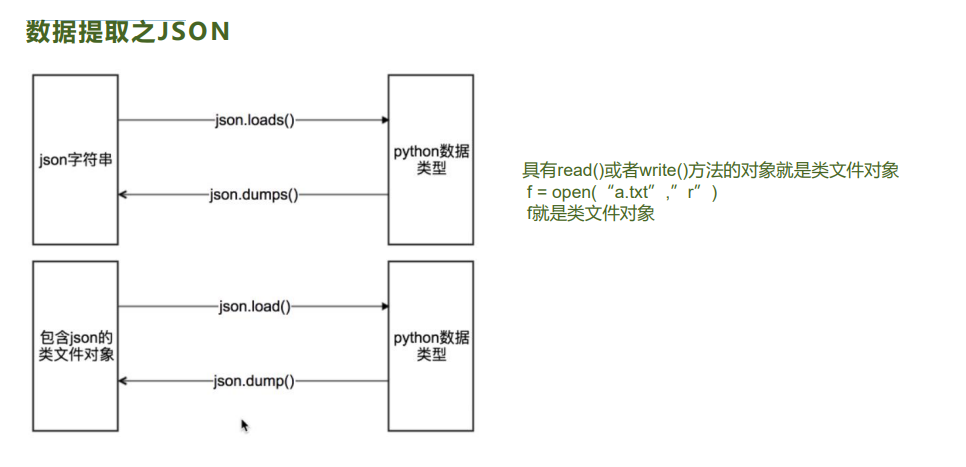
JSON(JavaScript Object Notation)
数据提取之JSON 1.为什么要学习json?
由于把json数据转化为python内建数据类型很简单,所以爬虫中,如果我们能够找到返回json数据的URL,就会 尽量使用这种URL,而很多地方也都会返回json
什么是json?
JSON 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写。同时 也方便了机器进行解析和生成。适用于进行数据交互的场景,比如网站前台与后台之间的数据交互。 3.哪里能找到返回json的url? 1.使用chrome切换到手机页面; 2.抓包手机app的软件
json使用注意点
json中的字符串都是用 双引号 引起来的,且必须是双引号 如果不是双引号 eval:能实现简单的字符串和python类型的转化 replace:把单引号替换为双引号 往一个文件中写入多个json串,不再是一个json串,不能直接读取 这时我们可以一行写一个json串,按照行来读取
7、动态网站数据抓取
什么是AJAX:
AJAX(Asynchronouse JavaScript And XML)异步JavaScript和XML。过在后台与服务器进 行少量数据交换,Ajax 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情 况下,对网页的某部分进行更新。传统的网页(不使用Ajax)如果需要更新内容,必须重载 整个网页页面。因为传统的在传输数据格式方面,使用的是XML语法。因此叫做AJAX,其 实现在数据交互基本上都是使用JSON。使用AJAX加载的数据,即使使用了JS,将数据渲染 到了浏览器中,在右键->查看网页源代码还是不能看到通过ajax加载的数据,只能看到使用 这个url加载的html代码。
获取ajax数据的方式:
直接分析ajax调用的接口。然后通过代码请求这个接口。
- 直接可以请求到数据,不需要做一些解析工作,代码和工作量少。
- 分析接口复杂。容易被发现时爬虫
使用Selenium+chromedriver模拟浏览器行为获取数据。
- 直接模拟浏览器的行为,浏览器能请求到的,使用selenium也能请求到,爬虫更加稳定
- 代码量多,性能低。
Selenium+chromedriver获取动态数据:
Selenium相当于是一个机器人。可以模拟人类在浏览器上的一些行为,自动处理浏览器上 的一些行为,比如点击,填充数据,删除cookie等。chromedriver是一个驱动Chrome浏览 器的驱动程序,使用他才可以驱动浏览器。当然针对不同的浏览器有不同的driver。
以下列 出了不同浏览器及其对应的driver:
Chrome: Firefox: Edge: Safari:
安装Selenium和chromedriver:
- 安装Selenium:Selenium有很多语言的版本,有java、ruby、python等。我们下载python 版本的就可以了。
1 | pip install selenium |
- 安装chromedriver:下载完成后,放到不需要权限的纯英文目录下就可以了
放到python编译器的目录下面即可
1 | #使用 Chrome + selenuim |
Notes:
如果只是想要解析网页中的数据,那么推荐将网页源代码扔给lxml来解析。因为lxml底层使用的是C语言,所以解析效率会更高。如果是想要对元素进行一些操作,比如给一个文本框输入值,或者是点击某个按钮,那么就必须使用selenium给我们提供的查找元素的方法。
8、BeautifulSoup
介绍:
- 对于一个网页来说,都有一定的特殊结构和层级关系,而且很多节点都有id或class来作区分,Beautiful Soup 就是借助网页的结构和属性等特性来解析网页,Beautiful Soup是一个强大的解析工具
- Beautiful Soup(简称BS4)提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。
- Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。
- BeautifulSoup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
- Beautiful Soup不需要考虑编码方式,除非文档没有指定,重新原始编码方式即可。
- BeautifulSoup()第一个参数是字符串,即传给BeautiflSoup对象,第二个参数为解析器类型(这里使用xlml),此时完成BeautifulSoup对象的初始化。然后,将这个对象赋值给soup变量,接下来,就可以调用soup的各个方法和属性解析这串HTML代码了。
如何遍历文档树?
直接子节点
.contents :标签的 .content属性可以将tag的子节点以列表的方式输出
.children:返回一个可迭代对象
所有子孙节点
.descendants属性可以对所有tag的子孙节点进行递归循环,和children类似,我们也需要遍历获取其中内容。
节点内容:
.string:返回标签里面的内容
.text:返回标签的文本
1 | from selenium import webdriver |
如何搜索文档树:
- find_all(name,attrs,recursive,text, **kwargs)
-
传入True:找到所有的Tag
1
2
soup.find_all('b') -
传入正则表达式 #通过正则找
1
2
3
4
5import re
for tag in soup.find_all(re.compile("^b")):
print(tag.string) 3.传入列表
#找a 和 b标签
soup.find_all(["a", "b"] -
传入列表
1
2#找a 和 b标签
soup.find_all(["a", "b"]) -
keyword参数(name,attrs)
1
2
3soup.find_all(id='link2')
#如果传入 href 参数,Beautiful Soup会搜索每个tag的”href”属性:
soup.find_all(href=re.compile("elsie")) -
通过text参数可以搜索文档中的字符串内容
1
2soup.find_all(text="Elsie")
soup.find_all(text=['Tillie','Elsie','Lacie']) -
限定查找个数-limit参数
1
soup.find_all("a",limit=2)
-
recursive参数
1
2#调用tag的 find_all方法,BeautifulSoup会检查当前tag的所有子孙节点,如果只想搜索tag的直接子节点,可是使 用参数recursive=False
soup.find_all('title',recursive=False)
1 | from bs4 import BeautifulSoup, Comment |
. 是任意字符 可以匹配任何单个字符,
例子:正则表达式r.t可以匹配这些字符串:rat、rut、r t,但是不匹配root。
.*? 表示匹配任意字符到下一个符合条件的字符
* 匹配0或多个正好在它之前的那个字符。例如正则表达式。*意味着能够匹配任意数量的任何字符。
? 匹配0或1个正好在它之前的那个字符。注意:这个元字符不是所有的软件都支持的。
.*是指任何字符0个或多个,
.?是指任何字符0个或1个.
.*具有贪婪的性质,首先匹配到不能匹配为止,根据后面的正则表达式,会进行回溯。
.\*?则相反,一个匹配以后,就往下进行,所以不会进行回溯,具有最小匹配的性质.
?表示非贪婪模式,即为匹配最近字符 如果不加?就是贪婪模式a.*bc 可以匹配 abcbcbc
其他
find_previous_siblings() ,find_previous_sibling()
这2个方法通过 .previous_siblings 属性对当前 tag 的前面解析的兄弟 tag 节点进行迭代,
find_previous_siblings() 方法返回所有符合条件的前面的兄弟节点, find_previous_sibling() 方法返回第一个符合条件的前面的兄弟节点
find_all_next() ,find_next()
这2个方法通过 .next_elements 属性对当前 tag 的之后的 tag 和字符串进行迭代,
find_all_next() 方法返回所有符合条件的节点
find_next() 方法返回第一个符合条件的节点
find_all_previous() 和 find_previous()
这2个方法通过 .previous_elements 属性对当前节点前面的 tag 和字符串进行迭代,
find_all_previous() 方法返回所有符合条件的节点,
find_previous()方法返回第一个符合条件的节点
CSS选择器
这就是另一种与 find_all 方法有异曲同工之妙的查找方法. 写 CSS 时,标签名不加任何修饰,类名前加.,id名前加#,在这里我们也可以利用类似的方法来筛选元素,用到的方法是 soup.select(),返回类型是 list。
(1)通过标签名查找 soup.select(‘a’)
(2)通过类名查找 soup.select(‘.sister’)
(3)通过 id 名查找 soup.select(‘#link1’)
(4)组合查找 soup.select(‘p #link1’)
(5)属性查找 soup.select(‘a[class=“sister”]’)
(6)获取内容 get_text()
1 | from bs4 import BeautifulSoup |